代码混淆——控制流扁平的开源实践和改进
孤挺花(Armariris): 由上海交通大学密码与计算机安全实验室维护的LLVM混淆框架,支持多平台、多语言。目前支持的功能主要有控制流混淆、指令替换、字符串加密。https://github.com/GoSSIP-SJTU/Armariris#armariris
本文主要对Armariris的控制流混淆实现代码进行分析,了解Armariris的实现方式。并对混淆强度进行部分改进。
下面先看下混淆前后的对比
混淆前
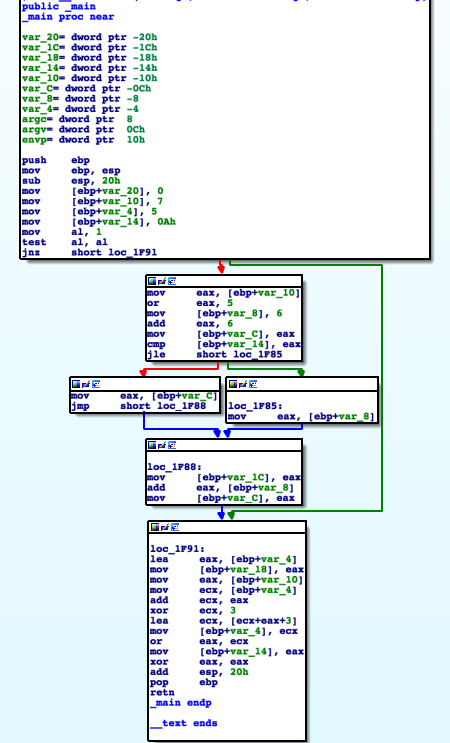
混淆后
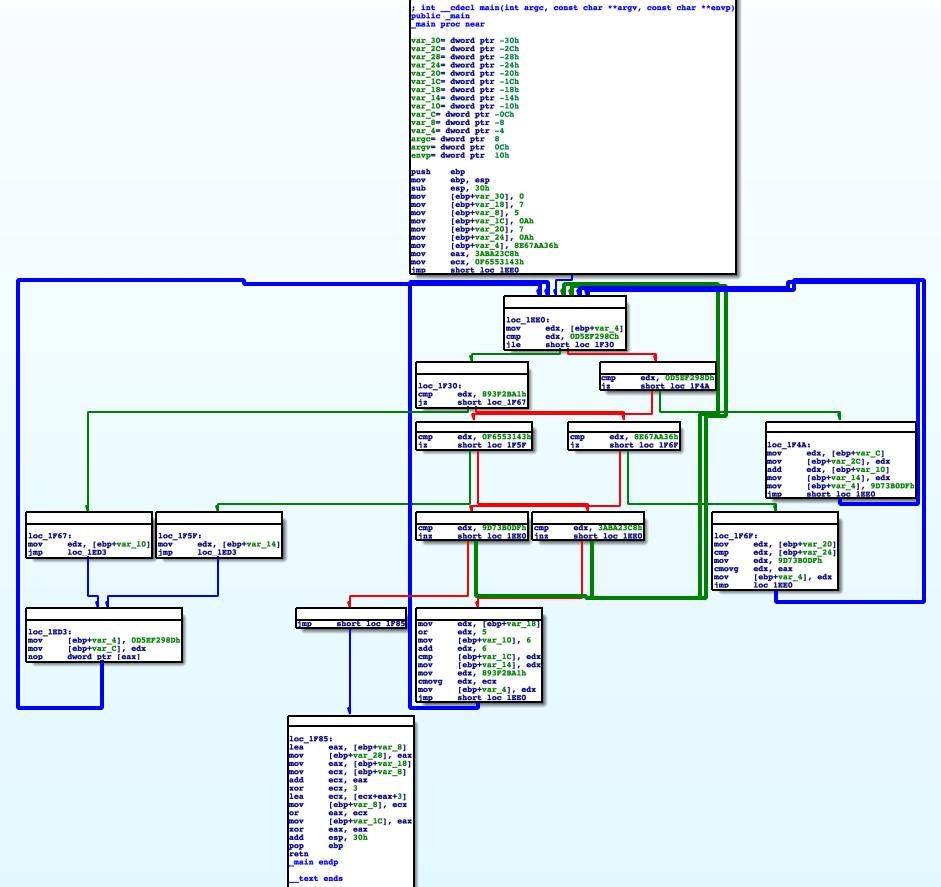
可以看到CFG的基本块变多了,控制流也变得复杂了。
Armariris脱胎于OLLVM,都是采用在LLVM中增加一个pass的方式来实现对源码的混淆处理。由于本身编译的混淆pass时静态库的形式存在的,不适合我们查看输出后的IR文件,也不适合调试,所以第一步我先对LLVM的编译方式进行修改。
1 | |
这是Armariris/lib/Transforms/Obfuscation路径下的cmake文件修改情况,如此一来我们就可以通过opt来load生成的LLVMObfuscation,单独进行混淆,而不必完成整个编译过程。
当然除了这个文件还需要修改一些LLVMBuild.txt和PassManager的cpp,解除原来静态库的依赖关系。这里就不详说了。
修改完成后进行编译就可以在编译好的lib文件夹下发现LLVMObfuscation.dylib,然后我们准备一个样例文件,long.cpp
1 | |
在里面填入简单的代码。
然后依次执行命令
1 | |
第一步先用clang输出long.cpp的中间语言文件——long.ll
第二步通过opt加载LLVMObfuscation.dylib执行混淆,输出的是LLVM的bitcode文件,是二进制格式,通过相应的工具也可以转换成IR文件
1 | |
然后我们查看混淆前的long.ll和混淆后的long-ir.ll有什么区别
1 | |
long.ll
1 | |
long-ir.ll
下面我们来分析Armariris的代码,看看它是如何实现的。控制流扁平化的伪算法在前一篇中已经介绍过了。当然由于实现方式方法有小小的不同,过程会略有差异,但是目标和大致过程都是相同的。
首先是入口函数
1 | |
Flattening是执行的混淆的主要类,我们在混淆命令中加入的 -flattening 就是为了指定调用Flattening。
为什么说runOnFunction是入口函数呢,这是由Pass的调用过程决定的。首先,opt会生成PassManager。PassManager有一个成员PM
1 | |
PM是PassManagerImpl类型,主要的执行类,启动通过内部的run函数启动PassManagerImpl。
1 | |
PassManagerImpl会选择相对应的内容管理者。getContainedManager返回FunctionPass的管理者MPPassManager
1 | |
通过多态,MP选择FPPassManager::runOnModule进入下一步
1 | |
1 | |
而Flattening也是继承于FunctionPass,所以runOnFunction也就成了Flattening的入口,从这里进入混淆函数flatten
到了这里,就正式进入了混淆的流程。我们先回顾一下上一篇代码混淆之道(二)中我们抽象出来的控制流扁平化算法:
标识符重命名(解决变量名冲突)——>控制语句展开(全变成if)——>变量声明提前——>控制流压扁
在IR文件中,由于LLVM的IR是SSA(静态单赋值形式)形式的,标识符重命名和变量声明提前这两步可以省略。而第二步中的控制语句的展开,高级语言中的For、While等循环结构已经都变成了条件判断+Branch的形式,可以理解为通常所说的if-goto的方式。只有switch的方式还保存着,所以只需要将仍然保存的switch也改写成条件判断+br跳转的形式即可。从这里也可以看出在IR层进行混淆的好处,大量的工作前端在生成IR的同时已经由编译器帮我们搞定了。
1 | |
flatten函数开始的时候执行各种声明,并且调用LowerSwitchPass。这个pass负责将IR文件中目前仍然存在的switch结构转化成if结构。
1 | |
origBB保存除第一个BasicBlock之外的所有BasicBlock。这里的BasicBlock就是IR层CFG的block,我们的FunctionPass所获得的Function都是以CFG的形式存在的。之所以第一个BasicBlock不保存是因为需要对它进行大刀阔斧的改动,包括分配用于switch判断的变量的内存和跳转如循环。
1 | |
将第一个块尾部的跳转内容(如果有的话)提取到一个新的BasicBlock中,并且放入到origBB中。
1 | |
接下来为switch所需要的变量switchVar分配内存,并产生两个新BasicBlock,loopEntry和loopEnd。在loopEntry中通过switch结构来判断接下来执行哪个BasicBlock,所有的BasicBlock最后都会将switchVar的值修改为再下一个BasicBlock对应的值,并且跳转到loopEnd,再由loopEnd重新回到loopEntry。
1 | |
生成新的switch结构,并且将origBB中的BasicBlock一一放入其中,每个BasicBlock所需要的switchVar则随机生成。
接下来就是对每个BasicBlock的尾巴部分进行修改,这里要分两种情况
第一种是无条件跳转,也就是上一个BasicBlock会直接跳转到下一个BasicBlock,或者说是它只有一个后继节点
1 | |
这种情况比较好办。我们只需要给switchVar赋后继BasicBlock的case number,然后将br loopEnd添加到结尾就好。
第二种情况是有条件跳转,也就是该BasicBlock有多个后继节点
1 | |
这里就需要将switchVar的case number赋值改为选择性的select指令。
基本整个流程都遵循了上一篇我们所讲到的控制流扁平化算法。但是这里我们仍然可以看出一些问题。比如对于一些较大的block,混淆过后仍然是巨大的一整块
混淆前
1 | |
混淆后
1 | |
如果被混淆的代码大多数都是这种大块大块的顺序语句的话,那混淆的意义就不是很明显。所以对于这种大块,我们需要把他们切割成小块。
可以添加如下代码
1 | |
首先计算下所有BasicBlock包含指令的数量,对与指令数量大于平均值的,我们对它进行split。
实现对于大块的切割后我们还可以在添加虚假的控制流结构,来增加混淆的复杂性。
将上面第三个for循环的内容稍微更改一下,就可以变成一个非常简陋版本的虚假控制流。
1 | |
这里我们将原本BasicBlock末尾的br指令删除,换成一个icmp+br的形式,只需要将保证每次跳转都能跳转到正确的block上,就可以了。
进化后的block变成如下情况
1 | |
上述的修改全部保存到github中 https://github.com/penguin-wwy/Armariris.git
clone到本地,checkout到dev_0分支即可查看,可直接编译运行、调试。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!