CPython Key-Sharing Dictionary优化
PEP 412 – Key-Sharing Dictionary
PEP-412来自2012年, 提出了对 dict 实现的改变,允许保存object属性的 dict 与同一类别实例的其他属性字典共享key列表。这种称为Split-Table dictionaries。
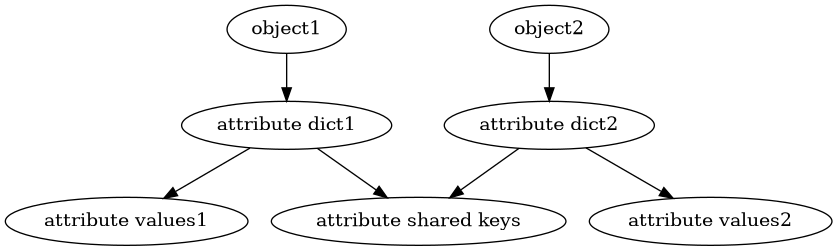
与之相反的不共享key列表的称为Combined-Table dictionaries。当创建一个对象的__dict__时,它们是以split的形式被创建的。键表被缓存在类型中,允许一个类的实例的所有属性字典共享键。如果这些字典的键开始出现分歧,那么就会从split模式转换为combine模式。
内存
通过将键(和哈希值)与值分开,就有可能在多个字典之间共享键,并改善内存的使用,这些字典的大小通常是当前字典实现的一半。
基准测试表明,面向对象的程序的内存使用减少了10%到20%,其他程序的内存使用没有明显变化。
速度
新的实现主要目的是内存优化。当键没有被共享时(例如在模块字典和由dict()创建的字典中),那么性能与当前的实现没有变化(在1~2%之内)。
对于共享键的情况,新的实现倾向于将键和值分开,但减少了总的内存使用。这在很多情况下会提高性能,因为减少内存使用的效果超过了局部性的损失,但有些程序可能会显示出小幅的减速。
基准测试显示,大多数基准测试的速度没有明显变化。面向对象的基准测试显示,当它们创建大量相同类别的对象时,速度会有小幅提升(gcbench基准测试显示有10%的速度提升,这可能是一个上限)。
内存改善
issue27350,该issue对key列表的内存使用进行了进一步优化。这个优化来自PyPy的实现,https://morepypy.blogspot.com/2015/01/faster-more-memory-efficient-and-more.html。简单来说就是用一个数组来记录hash槽位,这样dict entry就可以紧凑的放到一起。entry的大小要大于表示位置信息的整型,从而起到节省空间的作用。
优化前:

优化后:

3.11进一步优化
但是在issue27350加入之后产生了一个新的问题,就是当共享key的插入顺序不一致时,也需要转换为combine模式。例如:
a1 = A()
a2 = A()
a1.field1 = 1
a1.field2 = 2
a2.field2 = 2
a2.field1 = 1虽然a1和a2都是类型A且属性相同,但是由于插入顺序不一致,导致key列表的内存分布并不一致。
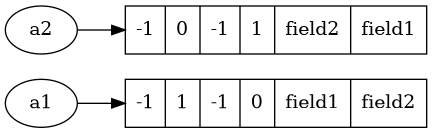
a2的__dict__就需要从split table变为combine table。
bpo-40116解决了这个问题,在split table的values列表中同样插入了一个排序数组,扩展了split table的使用范围。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!