OSDI2025 论文速读(1)
KPerfIR: Towards an Open and Compiler-centric Ecosystem for GPU Kernel Performance Tooling on Modern AI Workloads
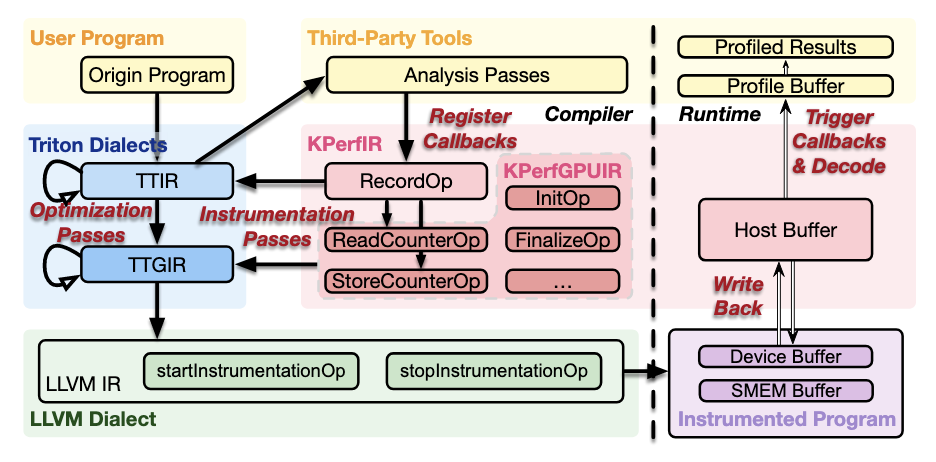

主要做法是增加dialect实现对于region层面的计时。比较有意思的地方在于对于sample数据的存储和统计。
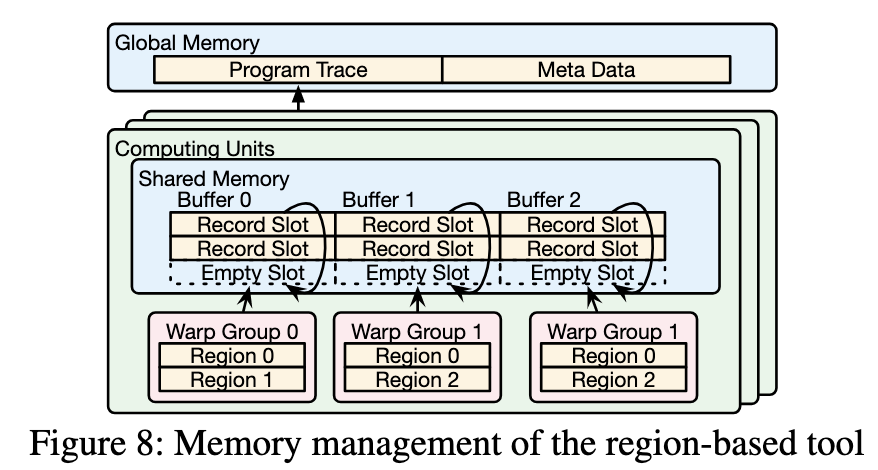
采样的时间戳会以一种滚动刷新的方式写入到smem来减少内存占用,也可以在slot占满后填入global mem。
NanoFlow: Towards Optimal Large Language Model Serving Throughput

For example, for the original Up projection operating on a batch size of 2048, NanoFlow could create two nanooperations UP1 and UP2, operating on batches in ranges 0-768 and 768-2048, respectively, while performing the exact same projection.
做法描述:
Profiling interference-free kernels
Profiling kernels with interference,包含不同类型算子两两组合的情况
根据上面两种profiling,构建出静态的不同资源分配情况下性能比例,以GEMM的性能作为基准
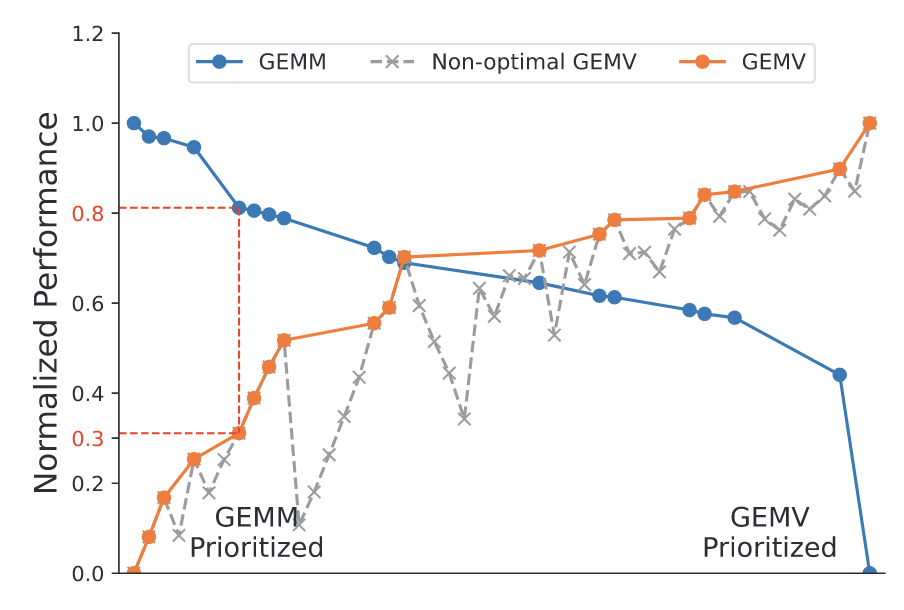
结合batch size大小就可以获得一个nano batch 1 和 nano batch 2的搜索空间,找出最优的pipeline
Example Pipeline
70B pipeline

PipeThreader: Software-Defined Pipelining for Efficient DNN Execution

TileLang的论文,感觉看懂这张图就够了。在pipeline编排时把专用硬件抽象出来,增加一个维度的搜索空间来寻找更优的结果。
可以和Mirage那篇进行一个对比。
OSDI2025 论文速读(1)
http://example.com/2025/09/11/osdi25-papers1/