Tracing the meta-level:\ PyPy's tracing JIT compiler
ABSTRACT
PyPy Meta-Tracing JIT的一个目标是简化动态语言高性能实现的方法。
PyPy项目一直以——总体上简化动态语言实现方法——为目标。它一开始是用RPython实现Python解释器,之后对实现其他动态语言也很有用。一般的方法是在Python的一个子集上实现一个语言解释器,这个子集可以被编译成各种目标环境,如ASC/POSIX、CLI或JVM。
许多动态语言使用字节码解释器,但是却没有更高级的即时编译技术。造成这种情况的原因有很多,其中大部分归结为使用编译的固有复杂性。解释器易于实现、理解、扩展和移植,而编写即时编译器是一项容易出错的任务,语言的动态特性使其更加困难。
编写基于Trace的JIT编译器则相对简单。它可以被添加到一种语言的现有解释器中,解释器接管了编译器的一些功能,机器代码生成部分可以得到简化。
在本文中,讨论了PyPy项目借助PyPy工具链提升的解释器性能的工作,也就是JIT。
与当前存在的动态语言Tracing JIT不同,PyPy所Trace的是“下一级”,即它跟踪解释器的执行,而不是用户程序的执行。
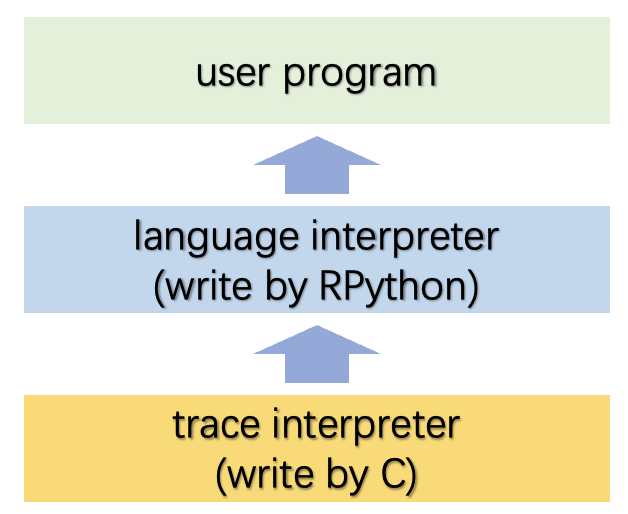
本文的核心贡献有两点:
- Applying a tracing JIT compiler to an interpreter.
- Finding techniques for improving the generated code.
Tracing JIT
首先考察一下Tracing JIT的相关内容。
对于动态语言的性能提升,tracing JIT是一个很不错的思路,它基于以下两个基本假设:
- programs spend most of their runtime in loops
- several iterations of the same loop are likely to takesimilar code paths
Trace JIT基于解释器在执行过程中通过轻量级的profiling,定位到用户代码的热路径(比如循环),解释器进入trace mode,在该模式下会跟踪记录足够的执行信息。这些跟踪获得的信息会用于生成高性能的机器代码,在下一次进入热路径的时候执行。
这种跟踪是连续的,它只表示代码的许多可能路径中的一条。为了确保正确性,路径其他方向上都包含一个保护(guard),例如在条件和间接或虚拟调用时。在生成机器代码时,每个guard都被转换某种快速检查,以保证我们正在执行的路径仍然有效,如果检查失败,会立即退出机器代码,并通过回退到解释来继续执行(Deoptimize)。
最重要的点在于解释器如何识别loop,即跟踪器如何识别它到目前为止记录的轨迹对应于一个循环。
这依赖于某种position key:如果该位置处之前已经被执行过一次。跟踪器不需要一直检查是否是position key,而只需要后向跳转时检查是否已经途径过该点(例如,反向分支指令)。注意,在正常解释执行期间,它们是执行剖析的地方(定位循环);在跟踪期间,它们是执行闭合循环检查的地方。
Applying a Tracing JIT to an Interpreter
Unrolling the bytecode dispatch loop
在简单了解Tracing JIT之后,考察PyPy所实现的Meta-level tracing JIT。
如前所述,PyPy跟踪的内容并不是用户程序执行的过程,而是解释器的执行过程(Meta-Level)。
对解释器而言,最重要的热循环是字节码分派循环(对于许多简单的解释器来说,它也是唯一的热循环)。此循环的一次迭代对应于一个操作码的执行。
这意味着Tracing JIT所做的假设之一是错误的——热循环的几次迭代并不能保证相似的代码路径。
为了优化这种情况,JIT就不能以单一执行的分派过程作为基准开始优化,它需要跟踪多条opcode的执行情况,这本质上类似于unrolling the bytecode dispatch loop。
理想情况下,字节码分派循环应该完全展开,并从中可以找到相对应的用户代码循环(当语言解释器的程序计数器几次具有相同的值时,就会出现用户循环)。和语言解释器类似,跟踪器,程序计数器出现相同的情况,意味着发现一个闭合的循环。不过对于跟踪器来说,这需要解释器协助完成。
这里对于language-interpreter的trace在概念上是由tracing interpreter完成的(因为RPython也是一种运行在解释器上的解释型语言,所以它的trace工作可以由本身的解释器替代),这里就形成了所谓的双解释器结构。
Improving the Result
之后便是对展开之后的执行序列进行优化,不过这篇论文里优化内容讲的并不多,简单提了下类似常量折叠之类的。
有个例子简单演示一下全过程。
首先是解释器代码:
1 | def interpret(bytecode, a): |
输入程序:
1 | MOV_A_R 0 # i = a |
跟踪生成的执行序列:
1 | loop_start(a0, regs0, bytecode0, pc0) |
优化之后
1 | loop_start(a0, regs0) |
最后
内容上没有太多值得关注的细节,有几点总结一下:
- 首先是对于Tracing JIT的论述,特别是循环识别、闭合;
- 其次Meta-Level层面上的实现方法;
- 在实现上有两点需要注意,
- PyPy本身的工具链会将RPython编译到C,所以生成的Interpreter本身就是Execution,论文中所谓的tracing-interpreter更多是对应于概念,实现时可以看做就是对C-interpreter的profiling;
- 同样需要oSR来做deopt的保障,而这本质是上双重解释器的实现机制上存在巨大差异,所需要的执行流、数据结构完全不同;