The Impact of Meta-Tracing on VM Design and Implementation
Introduction
这篇主要介绍Meta-Level tracing(其实就是PyPy)所实现的一些优化设计(找个了Converge来对比,但是不太熟,就跳过不看了)。前面对于Meta-Tracing的介绍没啥好看的。有一句总结性的描述:
The fundamental difference between meta-tracing and non-meta-tracingJITs is that the latter JIT must be manually written. By tracing the actionsthe interpreter itself takes, a meta-tracing JIT can automatically create aJIT from the interpreter.
这也符合PyPy自身设计的初衷。
Optimising an RPython VM
接下来是正题,一些优化上的设计。
General RPython JIT optimisation techniques
一些通用的优化技术。
promoting values:来自于Partial Evaluation中的promotion。
Elidable functions:简单来说就是相同输入会获得相同输出的函数,但是与pure function并不想等。
Using trace optimiser friendly code:某些代码并不适合trace优化,比如list的append操作,如果是变长的情况下,每次都需要去检查是否有足够的长度继续指向append操作,这无疑会提高deopt的概率。最简单的处理办法比如使用定长的数据结构来代替它,或者对于不需要随机访问的情况下用linked list代替。
Optimising Instances
对于PyPy这样的语言VM来说,最重要的优化无疑是对object model的优化(包括instance、class、module)。
对于Python这样的语言来说,本质上,instance的行为类似于将槽名称(作为字符串)映射到值的字典,而class定义了实例之间的共享行为(反过来说,与其他OO语言不同的是class并不能决定每个instance的shape)。语言的行为更接近prototype-basedlanguages,比如Self。

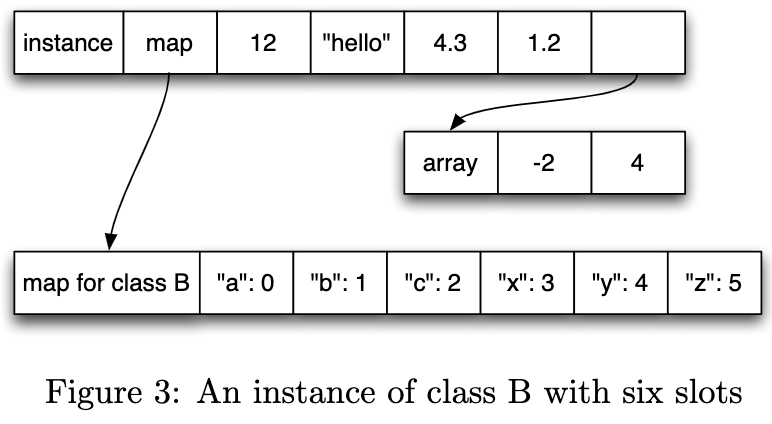
尽管class并不能约束每个instance的形状,但是在实践中,他们之间不一致的情况是少数。所以通过立即访问来代替字符串映射来提升访问速度,这一做法任然是可行的。例如上图,可以通过固定slot的方式,将a.x的访问优化成a.slot[0]。
此外,非正式研究表明,大多数instance的属性访问,集中在5个甚至更少。因此PyPy为5个插槽预分配空间,使其在大多数情况下无需分配任意大小的列表来存储插槽,当超出5个的时候再分配额外的变长插槽,如下图所示:
Python中的instance可以通过__dict__来访问全部properties。但是这样的语法会导致两个问题:一是字典是一个复杂的数据结构,需要额外的内存代价;
二是这会破坏很多优化的机会,比如上面的立即访问操作。因此,正常情况下PyPy任然使用列表的方式实现属性的立即访问,但是维护一个fake dict,当一个instance调用__dict__的时候,就会将属性使用字典重排。
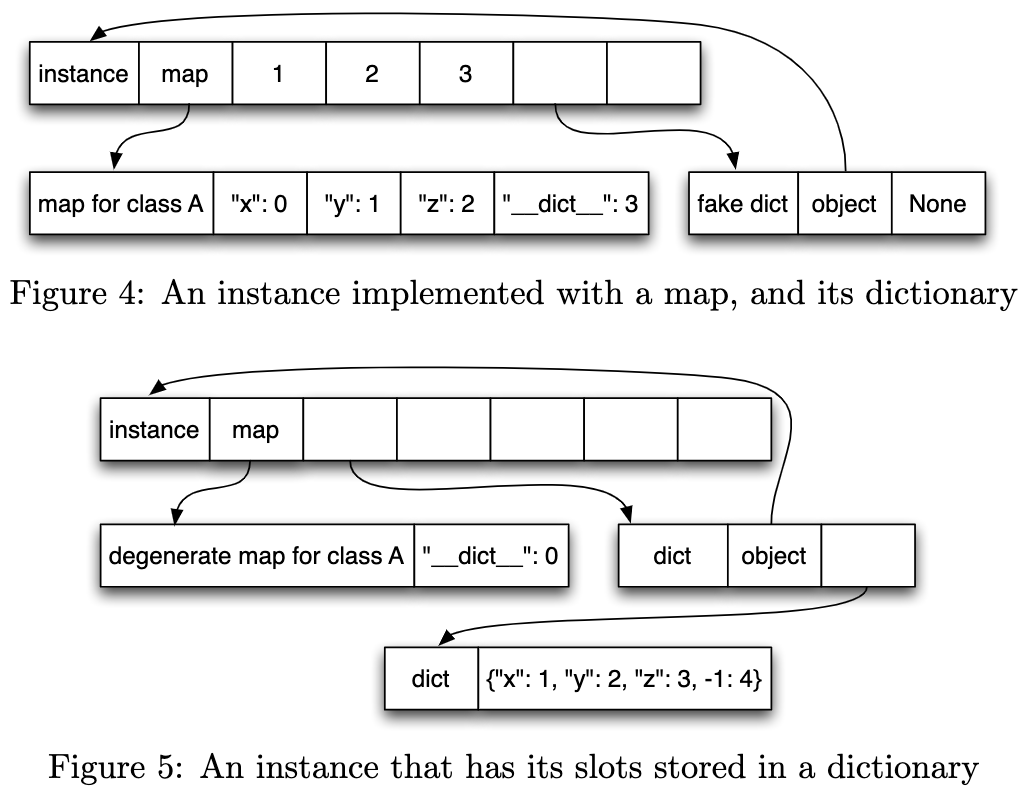
这也体现了,随着更罕见、更动态的特性的使用,解释器是如何逐渐降低性能的。
Optimising Classes
对于class的优化的关注点则变成了如何降低反射调用method上。不过对于method的查找需要考虑继承关系,所以代价更加昂贵。
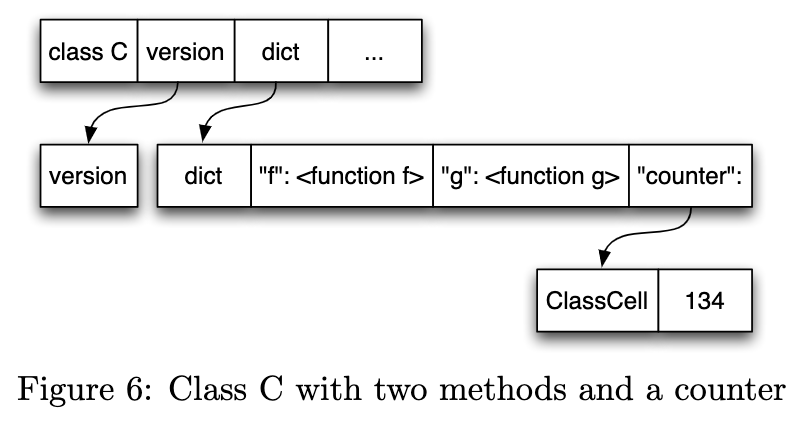
这里使用的优化方式叫类的版本化。对于一个特定版本的类,它对于某个字段的访问应该是一致的,那么查找只需要进行一次。这种技术使得在普通情况下在类中查找字段非常快速(在速度上与C++方法调用相当)。JIT将字段查找优化为单个保护,它只需要检查一个类版本;如果检查成功,则正确的结果已经知道并插入。
然而,如上所述,当类的字段频繁变化时(会导致版本频繁变化),性能将受到影响。例如有一个class field用于记录当前发生多少次实例化:
1 | class C: |
PyPy在上面增加了一层额外的间接级别:类不再直接存储该字段的值,而是存储对包含该值的Cell。当随后更改该特定字段时,只会更改该Cell的内容,而不会更改整个类:因此不需要更改类的版本。
Optimising Modules
Module的优化基本跟class相同。
Discussion
这些优化例证了RPython VM需要考虑哪些使用模式是最频繁的。然后,按照这种使用方式修改解释器和数据结构,以便与JIT一起生成代码少、保护少的机器代码。所以在演进过程中部分解释器的手动重写是必要的,许多优化依赖于对解释器实现的语言的深入了解。
同时必须对真正的程序进行分析,以确定需要关注哪些案例。不同的基准(合成的或非合成的)可以在很大程度上改变对最重要使用场景的看法,必须谨慎选择。